Spotlight: From Pipeline Chaos to Pipeline Zen
Every engineer has that moment where they stare at a system and think, “Why are we doing it this way?” For me at Zupa, that moment came when I opened their deployment pipelines. At first glance, they worked fine — but the deeper I looked, the more I saw a maze of duplication, fragile steps, and complexity just waiting to trip someone up.
🤔 The problem
Zupa’s deployment setup followed a pipeline per environment approach. On paper, this seemed logical: one pipeline for Dev, another for Test, and so on. In practice, it was a maintenance nightmare.
- Duplication everywhere: the same YAML code repeated across multiple files.
- Risk of inconsistency: a change made in one pipeline might be forgotten in another.
- Slowed delivery: adding a new environment meant spinning up yet another pipeline, copying and pasting logic, and hoping nothing was missed.
It worked, but it wasn’t elegant. And it certainly wasn’t scalable.
The team spent more time maintaining pipelines than delivering features. Each small change carried unnecessary risk, and the sheer repetition slowed everything down. What should have been an enabler of speed and confidence had become a drag on productivity.
✅ The solution
I proposed flipping the model on its head.
Instead of multiple pipelines per environment, I built a single unified pipeline that could flex to any environment.
- Stage-per-environment: deployments became stages within one pipeline.
- Job-per-component: each component of the system ran in its own job, cleanly separated.
- Parameterization: environment-specific details were abstracted into parameters passed into the pipeline, not baked into the YAML.
The effect was immediate. No more juggling dozens of nearly identical YAML files. Adding a new environment? Just provide parameters — no risky refactor needed. The pipeline itself stayed clean, consistent, and easy to evolve.
This gave lots of time back to the engineers and everyone was thankful for it
🛠️ The Implementation
(If you're not technical skip this part ...)
The implementation followed a component-based architecture, built around a core set of YAML files. The design kept the pipeline modular, clean, and easy to extend.
At a high level, the layout looked like this:
template_V2.yml— the core pipeline template, containing the reusable logic.solution_V2.yml— the main entry point that defined the pipeline stages per environment.component-loop_V2.yml— a looping construct to iterate through components, keeping jobs consistent and DRY.
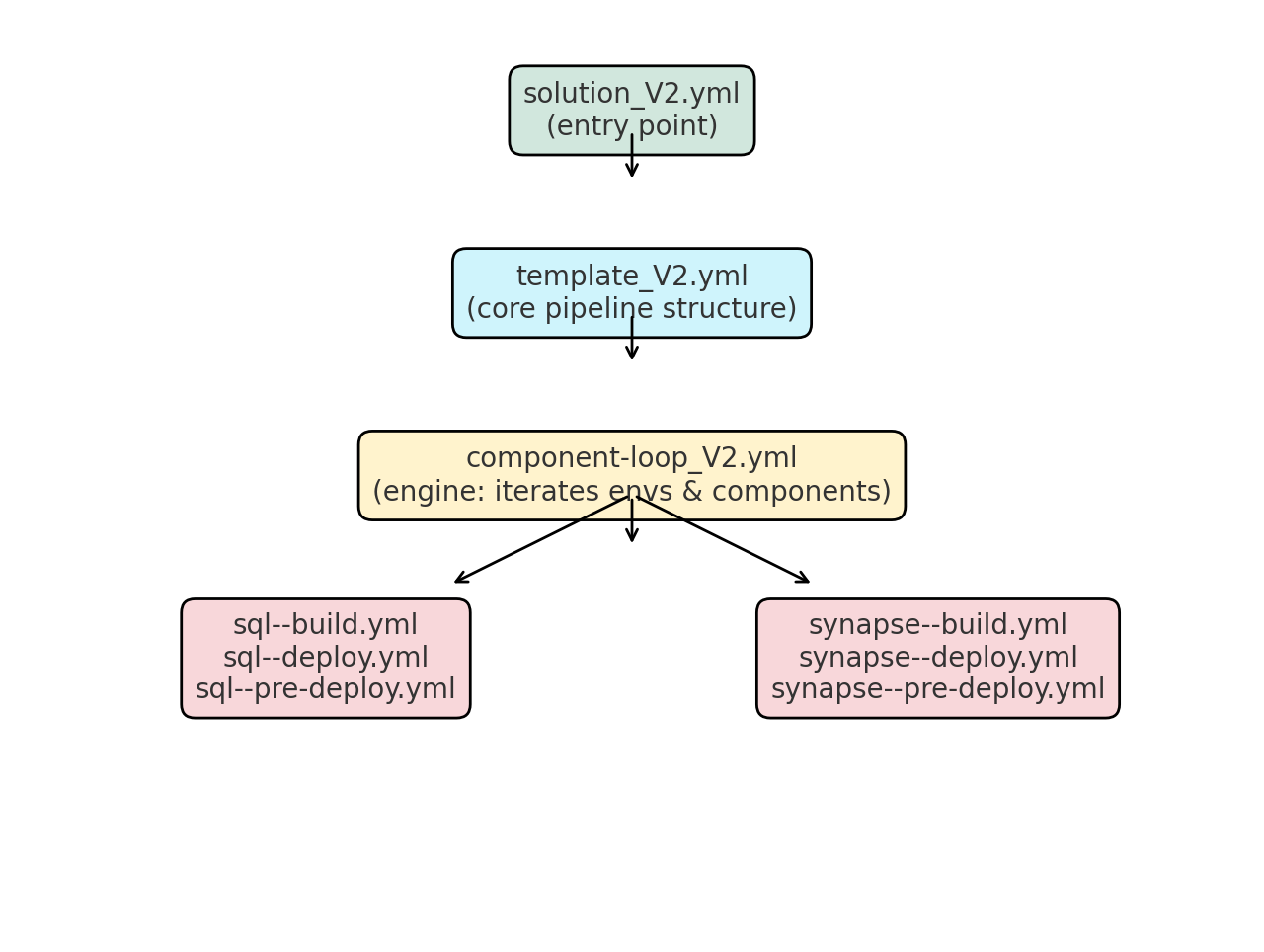
The core pipeline was agnostic to its components, allowing them to be managed independently ...
Below are the full YAML files that powered the solution:
📄template_v2.yml
This is the base template — every solution extends from it to ensure consistency. It defines the stages, environments, and core logic of the pipeline, while delegating repeated logic (like looping over components) to smaller templates.
Here is the full yml:
# The base template
## solution.yml MUST extend from this to ensure consistency
## Version: v2.0.0
## ChangeLog
### V2.0.0 - Added pre-deployment section and moved the component loop to its own template to reduce code duplication - CT
# Incoming Parameters - Passed from Solution.yml
parameters:
- name: config
type: object
- name: components
type: object
default: []
# Environments
## Stage Definitions
- name: stages
type: object
default:
- type: DEV
name: development
- type: REL
name: release
# Environment Config
- name: environments
type: object
default:
- type: DEV
name: DEV03
azureServicePrincipal: DevOps_[Company]Platform_DEV_GM
azureSynapseWorkspace: [Company]dev03datasynws01uks
azureSynapseResourceGroup: [Company]dev03coresynapseuksrg
azureSynapseAnalyticsConnectionString: Integrated Security=False;Encrypt=True;Connection Timeout=30;Data Source=[Company]dev03datasynws01uks.sql.azuresynapse.net;Initial Catalog=[Company]datasqldb01
azureCoreKeyVault: [Company]dev03corekv01uks
azureDataLake: [Company]dev03datadlsa01uks
azureSearchApi: 'https://[Company]dev03searchacs01uks.search.windows.net/indexes/products/docs/index?'
azuredataKeyVault: [Company]dev03datakv01uks
azureDedicatedSqlEndpoint: [Company]dev03datasynws01uks.sql.azuresynapse.net
## Release
- type: REL
name: REL02
azureServicePrincipal: RELEASE02(4b018bbd-ec0f-4483-8f0e-c68e957930fd)
azureSynapseWorkspace: [Company]rel02datasynws01uks
azureSynapseResourceGroup: [Company]rel02coresynapseuksrg
azureSynapseAnalyticsConnectionString: Integrated Security=False;Encrypt=True;Connection Timeout=30;Data Source=[Company]rel02datasynws01uks.sql.azuresynapse.net;Initial Catalog=[Company]datasqldb01
azureCoreKeyVault: [Company]rel02corekv01uks
azureDataLake: [Company]rel02datadlsa01uks
azureSearchApi: 'https://[Company]rel02searchacs01uks.search.windows.net/indexes/products/docs/index?'
azuredataKeyVault: [Company]rel02datakv01uks
azureDedicatedSqlEndpoint: [Company]rel02datasynws01uks.sql.azuresynapse.net
stages:
### Build Stages ###
- ${{ if eq(parameters.config.isBuild, true)}}:
- stage: Build
jobs:
- ${{ each component in parameters.components }}:
- job: build_${{component.name}}
displayName: 'Build ${{component.name}}'
steps:
- template: /build/YAML/components/${{component.type}}/${{component.type}}--build.yml
parameters:
component: ${{component}}
### Deploy Stages ###
#### Pre-Deployment
- ${{ if eq(parameters.config.isDeploy, true)}}:
- ${{each stage in parameters.stages}}:
- stage: preDeploy_${{stage.name}}
displayName: "Pre-Deploy ${{stage.name}}"
jobs:
- template: /build/YAML/templates/component-loop_V2.yml
parameters:
isPreDeploy: true
stage: ${{stage}}
components: ${{parameters.components}}
config: ${{parameters.config}}
environments: ${{parameters.environments}}
#### Deployment
- stage: deploy_${{stage.name}}
dependsOn: preDeploy_${{stage.name}}
displayName: "Deploy ${{stage.name}}"
jobs:
- template: /build/YAML/templates/component-loop_V2.yml
parameters:
isPreDeploy: false
stage: ${{stage}}
components: ${{parameters.components}}
config: ${{parameters.config}}
environments: ${{parameters.environments}}
Key highlights:
- Parameters: Accepts config and component lists from the solution file.
- Environment Config: Defines per-environment settings like service principals, key vaults, Synapse workspaces, and connection strings.
- Stages:
- Build — loops through components and builds each one using its own type-specific build template.
- Pre-Deploy — added in v2.0.0 to prepare each component before deployment.
- Deploy — runs the actual deployment jobs, reusing the
component-loop_V2.yml.
- Abstraction: By moving the component loop to a separate template, this file avoids duplication and stays lean.
📄solution_v2.yml
This file defines the solution structure and solution-specific configuration. Think of it as the entry point for the deployment pipeline: it pulls in the core template_V2.yml and then describes which components to deploy, their types, and any special parameters they need.
# This template defines the solution structure as well as solution specific config
## Version: 2.0.0
## Author: Corbin Taylor
## Notes:
### V2 - Added pre-deployment per component
parameters:
- name: config
type: object
extends:
template: /build/YAML/templates/template_V2.yml
parameters:
config: ${{parameters.config}}
components:
- type: sql
name: SQLArtifacts
hasPreDeploy: true
targetEnvironments: REL
displayName: "SQL Artifacts"
dedicatedSQLPoolName: [Company]datasqldb01
dacPacArguments: '/p:IgnoreUserSettingsObjects=true
/p:IgnoreLoginSids=true
/p:IgnoreRoleMembership=true
/p:IgnorePermissions=true
/p:DropObjectsNotInSource=true
/p:ExcludeObjectTypes=Users;Logins;RoleMembership'
- type: synapse
name: SynapseArtifacts
hasPreDeploy: true
targetEnvironments: ALL
displayName: "Synapse Artifacts"
templateFile: $(Pipeline.Workspace)\synapse-ci\ARMTemplates\ARM\TemplateForWorkspace.json
templateParametersFile: $(Pipeline.Workspace)\synapse-ci\ARMTemplates\ARM\TemplateParametersForWorkspace.json
workspaceFolder: [Company]dev03datasynws01uksKey highlights:
- Extends the core template (
template_V2.yml) so the main logic lives there, not here. - Parameters allow flexible config injection.
- Component list defines what gets deployed:
- SQL Artifacts: deployed with a set of
dacPacArguments, includes a pre-deployment step. - Synapse Artifacts: includes ARM template references and points to a workspace folder.
- SQL Artifacts: deployed with a set of
- Notes section tracks version history and intent (e.g. V2 added pre-deploy per component).
📄component_v2.yml
This template is the workhorse of the system. Its job is to iterate through environments and components and then decide whether to run pre-deployment or deployment steps.
parameters:
- name: isPreDeploy
type: boolean
default: false
- name: environments
type: object
- name: components
type: object
- name: config
type: object
- name: stage
type: object
jobs:
- job: diag_allEnvs
pool:
name: [Company]DeploymentPool02
displayName: "Diagnostic job for all envs in the stage"
condition: eq(variables['System.debug'], 'true')
steps:
- powershell: Write-Host isPreDeploy = ${{parameters.isPreDeploy}}
- ${{each targetEnvironment in parameters.config.targetEnvironments}}:
- ${{if contains(targetEnvironment.name, parameters.stage.type )}}:
- ${{each environment in parameters.environments}}:
- ${{ if eq(environment.name, targetEnvironment.name)}}:
- ${{ each component in parameters.components }}:
- ${{ if or(contains(component.targetEnvironments, environment.type), eq(component.targetEnvironments, 'ALL'))}}: # IF PIPELINE NOT RUNNING CHECK THIS TRIGGER
- ${{ if eq(parameters.isPreDeploy, 'true')}}:
- ${{ if eq(component.hasPreDeploy, 'true')}}:
## Pre-Deployment Diagnostics
- job: diag_preDeploy_${{component.name}}_${{targetEnvironment.name}}
condition: eq(variables['System.debug'], 'true')
displayName: "Diagnostic job for pre-deployment of ${{component.name}} on ${{environment.name}}"
steps:
- powershell: Write-Host Executing Pre-Deployment Diagnostic job for ${{component.name}} on env- ${{environment.name}}
## Pre-deployment file for each component
- deployment: preDeploy_${{component.name}}_${{targetEnvironment.name}}
displayName: "Pre-Deploy ${{component.name}} to ${{targetEnvironment.name}}"
environment: ${{parameters.stage.name}}--pre-deploy
strategy:
runOnce:
deploy:
steps:
- template: /build/YAML/components/${{component.type}}/${{component.type}}--pre-deploy.yml
parameters:
component: ${{component}}
environment: ${{environment}}
- ${{ if not(eq(parameters.isPreDeploy, 'false'))}}:
## Deployment Diagnostics
- job: diag_Deploy_${{component.name}}_${{targetEnvironment.name}}
condition: eq(variables['System.debug'], 'true')
displayName: "Diagnostic job for deployment of ${{component.name}} on ${{environment.name}}"
steps:
- powershell: Write-Host Executing Deployment Diagnostic job for ${{component.name}} on env- ${{environment.name}}
## Deployment file for each component
- deployment: deploy_${{component.name}}_${{targetEnvironment.name}}
displayName: "Deploy ${{component.name}} to ${{targetEnvironment.name}}"
environment: ${{parameters.stage.name}}--deploy
strategy:
runOnce:
deploy:
steps:
- template: /build/YAML/components/${{component.type}}/${{component.type}}--deploy.yml
parameters:
component: ${{component}}
environment: ${{environment}}
config: ${{parameters.config}}
Key highlights:
- Parameters: Controls whether this is a
preDeployordeployrun, and passes in the relevant environment + component configuration. - Diagnostic jobs: Only run if
System.debugis true, so you can toggle verbose diagnostics without touching the main logic. - Environment targeting: Loops through
targetEnvironmentsand ensures that only the right jobs run for the right environment. - Conditional logic:
- If
isPreDeploy= true and the component supports pre-deployment → run--pre-deploy.yml. - Otherwise → run the standard deployment (
--deploy.yml).
- If
- Reusability: Instead of duplicating deployment steps for every component and environment, it plugs into type-specific templates (
${component.type}--deploy.ymlor--pre-deploy.yml).
Reflection
That project taught me something crucial: just because a system “works” doesn’t mean it’s right. Automation should make life easier, not pile on hidden complexity. By simplifying the pipelines, I reduced risk, gave the team confidence, and created a structure that could grow without breaking.